
 Dr-Swopt
Dr-Swopt
Modificáronse 13 ficheiros con 103 adicións e 16 borrados
+ 4
- 3
ai-data-entry-ui/src/app/components/claim-form/claim-form.component.html
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 15
- 2
ai-data-entry-ui/src/app/components/claim-form/claim-form.component.ts
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 8
- 5
backend/main.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 37
- 6
backend/services/openai_service.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 1
- 0
requirements.txt
|
||
|
||
|
||
|
||
|
||
BIN=BIN
sample_medical_receipts/MY-1.jpg
{kind=link}

BIN=BIN
sample_medical_receipts/Screenshot 2026-03-31 080328.png
{kind=link}

BIN=BIN
sample_medical_receipts/WhatsApp Image 2026-03-31 at 7.58.22 AM.jpeg
{kind=link}

+ 38
- 0
sample_medical_receipts/fake_medical_receipt.pdf
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 0
sample_medical_receipts/sample_Med_claim.jpg → sample_medical_receipts/hospitalAmpang.jpg
{kind=link}

+ 0
- 0
sample_medical_receipts/cuepacscare3.jpg → sample_medical_receipts/kpj.jpg
{kind=link}
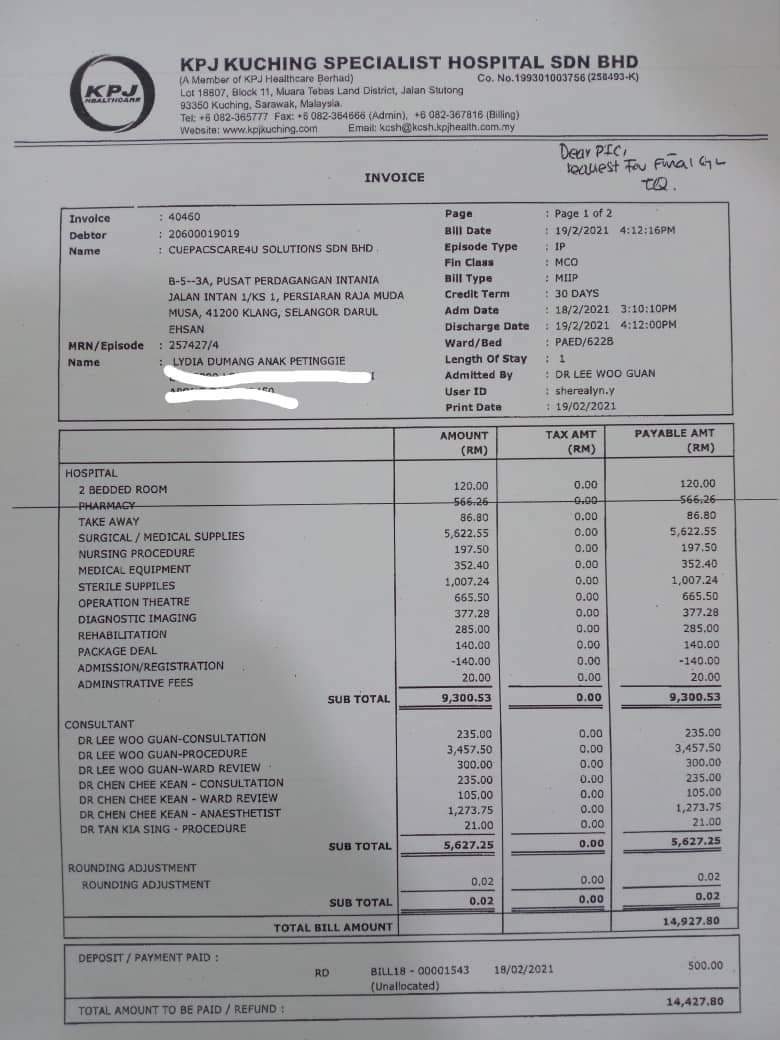
BIN=BIN
sample_medical_receipts/malay.png
{kind=link}

+ 0
- 0
sample_medical_receipts/ET3NmELUEAEXVu3.jpg → sample_medical_receipts/poliklinik.jpg
{kind=link}
